Γιατί ένας χαρακτήρας Telugu Bricking Apple Devices
Η Apple έχει ένα buggy λίγους μήνες. Τώρα έχουμε ένα νέο, σοβαρό σφάλμα στη λειτουργικότητα rendering κειμένου στα iPhones. Το σφάλμα ενεργοποιείται από έναν μόνο χαρακτήρα Telugu ο οποίος μπορεί να προκαλέσει σε ένα iPhone να εισέλθει σε ένα άθραυστο βρόχο εκκίνησης μόλις λάβει μια ειδοποίηση που περιέχει τον χαρακτήρα. Ας δούμε γιατί ένας μόνο χαρακτήρας μπορεί να προκαλέσει τέτοια σημαντικά προβλήματα με το iOS.
Σημείωση: Μια λύση για το σφάλμα Telugu είναι διαθέσιμη στην πιο πρόσφατη έκδοση του iOS (11.2.6). Εάν ο χαρακτήρας Telugu έχει κλειδώσει την εφαρμογή ή τη συσκευή σας, επαναφέρετε το iPhone σας μέσω του iTunes και ενημερώστε την στην πιο πρόσφατη έκδοση του iOS. Αν το iPhone σας έχει κολλήσει σε βρόχο εκκίνησης, ίσως χρειαστεί να το βάλετε στην κατάσταση ενημέρωσης υλικολογισμικού συσκευής (DFU) για να λάβετε το iTunes για να το αναγνωρίσετε. Όταν τελειώσετε, επαναφέρετε τη συσκευή σας από το τελευταίο αντίγραφο ασφαλείας που δημιουργήσατε ελπίζω.
Τι είναι το Telugu;

Το Τελούγκου είναι μια γλώσσα που μιλιέται και γράφεται σε μέρη της Ινδίας, συγκεκριμένα στα κράτη Άντρα Πραντές, Τελανγκάνα και στην πόλη Γιάναμ. Όπως πολλές γλώσσες που βασίζονται σε δέσμες ενεργειών, όπως τα αραβικά και άλλα γραπτά Brahmic, το Telugu χρησιμοποιεί μερικά ειδικά χαρακτηριστικά του χαρακτήρα χαρακτήρων Unicode για να εμφανίζει τους χαρακτήρες του σε μια οθόνη υπολογιστή.
Ενώ τα περισσότερα λατινικά γράμματα αντιπροσωπεύονται από ένα ενιαίο σημείο κώδικα Unicode 8-bit για συμβατότητα ASCII (για παράδειγμα, το γράμμα Α υπάρχει στο σημείο κώδικα Unicode U+0041, το οποίο αναπαρίσταται στο δυαδικό με 01000001 ) Τα λατινικά γράμματα συνήθως συνδυάζουν περισσότερα από ένα σημεία κώδικα Unicode για να αντιπροσωπεύουν τους χαρακτήρες τους.
Αυτό ισχύει ιδιαίτερα για τις γλώσσες, όπως το Telugu, που συνδυάζουν τις εκδοχές των γλωσσών σε συστάδες. Σε αντίθεση με τους στυλιστικούς δεσμούς της αγγλικής γλώσσας, η σύνδεση μεταξύ κάθε επιστολής της Telugu είναι γλωσσικά σημαντική. Για να γίνει αυτό, το Unicode περιλαμβάνει ένα πολύπλοκο σύστημα προσαρτημένων χαρακτήρων, το καθένα από τα οποία αντιπροσωπεύεται από το δικό τους σημείο κώδικα, το ένα στο άλλο.
Λαμβάνοντας υπόψη τον τεράστιο αριθμό κωδικών Unicode, αυτό μπορεί να δημιουργήσει σχεδόν άπειρη ποικιλία. Αυτά τα σημεία συνδυάζονται για να δώσουν έναν ευανάγνωστο χαρακτήρα. Με αυτόν τον τρόπο, το Unicode δεν χρειάζεται σημείο κωδικού Unicode για κυριολεκτικά κάθε πιθανή λέξη Telugu. Αντίθετα, το Unicode συνδυάζει τα σύμβολα της Telugu, τα φωνήεντα και τα diacritice ("virama") μαζί για να δημιουργήσουν λέξεις που εμφανίζονται σαν ένα μόνο χαρακτήρα. Το ίδιο ισχύει και για άλλες γλώσσες με ορθογραφικούς κανόνες για συνδέσμους, όπως τα αραβικά.
Τι προκαλεί τη συντριβή;

Το πρόβλημα φαίνεται να σχετίζεται με το Μη Ζυγιστήριο μηδενικού μήκους (ZWNJ) στο σημείο κώδικα U+200C . Το ZWNJ ζητά να γίνουν δύο γειτονικοί χαρακτήρες χωρίς την τυπική τους σύνδεση. Στα αγγλικά, ένα ZWNJ κρατά τους χαρακτήρες ff από το να τυπωθούν με τον τυπικό σύνδεσμο σύνδεσης τους, αντί να χωρίζουν κάθε f. Αλλά όταν συνδυάζεται με ένα συγκεκριμένο σύνολο τεσσάρων σημείων κώδικα Telugu (όλα τα οποία πρέπει να συνδυαστούν σε ένα μόνο σύμπλεγμα), για κάποιο λόγο το iOS δεν μπορεί να εμφανίσει σωστά το αποτέλεσμα.
Μερικοί έχουν υποθέσει ότι η γραμματοσειρά του San Francisco της Apple δεν μπορεί να εμφανίσει το χαρακτήρα, ενώ άλλοι έχουν πει ότι η συγκεκριμένη διαδικασία επεξεργασίας που χρησιμοποιεί η Apple είναι φταίξιμη. Όποια και αν είναι η ακριβής αιτία, η προσπάθεια να καταστεί ο χαρακτήρας προκαλεί μια δραματική σύγκρουση για ό, τι το κάνει, από τα μηνύματα και το WhatsApp στο Springboard. Τα σημεία κώδικα Unicode που συνθέτουν τον χαρακτήρα ("gya" που σημαίνει "γνώση") είναι παρακάτω:
U+0C1Cja (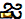 ),
),U+0C4Dένα σήμαU+0C4Dή diacritic ( ),
),U+0C1Enya (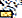 ),
),U+200Cμηδενικού μήκους πλάτουςU+0C3Eaa (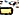 ),
),
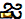 ),
), ),
),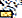 ),
),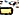 ),
),Αλλά δεν μπορούμε να κατηγορούμε ούτε το μη μηδενικό μηδενικό (ZWNJ) μόνο. Χρησιμοποιείται επίσης στα αθώα οικογενειακά emojis (???;) χωρίς κανένα πρόβλημα. Φαίνεται να είναι ένας συγκεκριμένος συνδυασμός ορισμένων ειδικών κωδικών σημείων και του ZWNJ. Προσθέτοντας προσβολή σε τραυματισμό, φαίνεται ότι το ZWNJ είτε δεν έχει ιδιαίτερη επίδραση στην απόδοση σε αυτό το σύμπλεγμα του Telugu, είτε ότι δεν πρέπει να υπάρχει καν στην πρώτη θέση.
Άλλα προβλήματα του Brahmic Script
Ωστόσο, η Telugu δεν είναι η μόνη γλώσσα με αυτό το ζήτημα. Οι Bengali και Devanagari, που χρησιμοποιούν το Unicode με παρόμοιο τρόπο για τα γραπτά Brahmic, έχουν το ίδιο πρόβλημα. Ο Manish Goregaokar γράφει μια αναλυτική και αναλυτική αναρτήση ιστολογίου που σπάει ακόμη περισσότερο την ακριβή περίπτωση σύγκρουσης:
Οποιαδήποτε ακολουθία
σε Devanagari, Bengali και Telugu, όπου:1. το
pstfείναι το επίθεμα που ενώνει (pstf/vatu)
2. ηconsonant1δεν είναι μια επιστολή εκτύπωσης
3. Τοvowelδεν έχει δύο συστατικά glyph
Συμπέρασμα: Γιατί δεν ήταν αυτό που συλλαμβάνεται από την Apple;
Για να καταλάβετε πώς έχει γίνει αυτό το σφάλμα, πρέπει να τοποθετήσετε τον εαυτό σας στα παπούτσια της Apple. Σίγουρα, αυτός ο συνδυασμός χαρακτήρων δεν είναι κάποια σούπερ σκοτεινή λέξη στη γλώσσα του Telugu. Αλλά το iPhone περιλαμβάνει υποστήριξη για δεκάδες γλώσσες. Υπάρχουν κυριολεκτικά δισεκατομμύρια πιθανών συνδυασμών στο Unicode. Με αυτή τη μεγάλη ποικιλία, η ουσιαστική δοκιμή για σφάλματα Unicode πριν από την απελευθέρωση θα καθιστούσε ουσιαστικά αδύνατη την τακτική ενημέρωση λογισμικού.
Ωστόσο, το λάθος δεν θα έπρεπε να έχει προκαλέσει αυτή τη μεγάλη ζημιά. Τα τηλέφωνα δεν πρέπει να μπλοκάρουν με βάση το περιεχόμενο ενός μηνύματος κειμένου. Ενώ η εκ των υστέρων είναι σίγουρα 20/20, φαίνεται ότι η απόδοση του χαρακτήρα ως κουτιού ερωτηματικού ( ) θα ήταν καλύτερη από τη συντριβή του Springboard.